Introduction
Une série temporelle est une séquence ordonnée d’instants, chaque instant étant associé à une valeur. Ce type de donnée est répandu dans de nombreux domaines, l’IoT en tête. Facebook a conçu un système nommé Gorilla afin de collecter, stocker et exploiter toutes les métriques rapportées par son infrastructure (charge CPU, taux d’utilisation des machines, température des disques durs, etc.).
Un élément innovant de leur système est la manière dont les séries temporelles y sont encodées. Elle permet une très bonne compression des données sans perte, ce qui réduit l’espace disque utilisé ainsi que le temps et les ressources nécessaires à son traitement. L’article scientifique rédigé par les auteurs de Gorilla décrit l’approche suivie en détail, je n’en exposerai ici que les caractéristiques qui me semblent les plus intéressantes.
Un monde prévisible
Toute technique de compression dans un système d’encodage repose sur l’idée que les données à encoder ne sont pas complètement aléatoires : elles présentent une structure, une tendance qu’il est possible d’exploiter afin d’en proposer une représentation efficace. Par exemple, dans un texte, certaines lettres et certains mots sont plus fréquents que d’autres. Il est alors possible de leur attribuer un encodage plus compact, quitte à ce que les lettres ou les mots plus rares aient, en contrepartie, un encodage moins performant.
Lorsqu’on mesure l’évolution de la température d’un processeur ou celle de l’utilisation de la mémoire vive d’une machine virtuelle, ces données changent continuellement, mais de manière souvent prévisible. La température ne change que dans la limite permise par la physique et les systèmes de contrôle. La mémoire vive est occupée et libérée au gré de l’exécution des programmes qui l’exploitent.
Gorilla tente d’exploiter au mieux cette prédictibilité pour proposer un encodage aussi efficace que possible. Les séries sont encodées séparément. Les dates et les valeurs bénéficient également d’un encodage distinct. Dans les deux cas, l’encodage se base sur la dernière ou les deux dernières valeurs enregistrées, ce qui limite l’empreinte mémoire de l’encodeur. Cette approche est appropriée pour l’encodage de mesure à la volée.
Encodage de dates
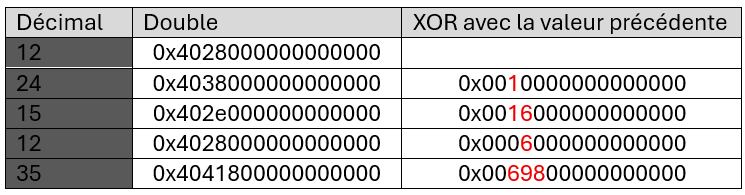
La gestion de l’horodatage est, par nature, essentielle dans les séries chronologiques. Les ingénieurs de Facebook ont remarqué que la très grande majorité (96.4%) des données arrivent à intervalle régulier. Par exemple, une mesure peut être prise toutes les 60 secondes. Il peut arriver qu’une donnée ait une seconde d’avance ou de retard, mais les intervalles de temps sont très constants. En conséquence, plutôt que d’encoder des dates entières, des delta-de-delta de dates sont enregistrés.
La première date d’une série chronologique est encodée sur 14 bits. Par la suite, pour une date tn, on calcule d1= tn – tn-1 et d2 = tn-1– tn-2. La valeur encodée est alors l’écart entre d1 et d2. En d’autres termes, on n’encode que l’écart entre la variation réelle et celle prédite par les deux valeurs précédentes.
Lorsque les dates sont parfaitement régulières, cet écart est nul. En général, on s’attend à ce qu’il soit faible. On l’encode donc en faisant en sorte que les petites valeurs soient représentées de manière plus compacte que les grandes. Gorilla utilise pour ce faire une approche particulière qui s’inspire de l’encodage en zig-zag. En particulier, un écart nul (qui survient lorsque la fréquence est constante) est encodé par un seul bit ‘0’.
Encodage de valeurs
Les ingénieurs de Facebook ont fait une double observation. Premièrement, les valeurs ont tendance à peu évoluer d’une valeur à l’autre, au regard de la plage des valeurs représentables. Ensuite, certaines de ces valeurs sont effectivement entières : il peut s’agir d’un comptage (nombre de fois qu’une page a été consultée, nombre de nœuds disponibles dans un cluster, …) ou de la représentation d’un état discret par un entier, par exemple.
Dans les deux cas, cela signifie que la plupart des bits représentant les valeurs en virgule flottante double précision (seul type supporté par Gorilla) ne changent pas d’une mesure à l’autre. De plus, ces bits inchangés sont situés au début et à la fin de la représentation binaire de la valeur, tandis que les bits modifiés se trouvent au cœur de la représentation. Gorilla appelle la plage des bits modifiés les bits significatifs, et exploite cette plage pour encoder les valeurs efficacement.
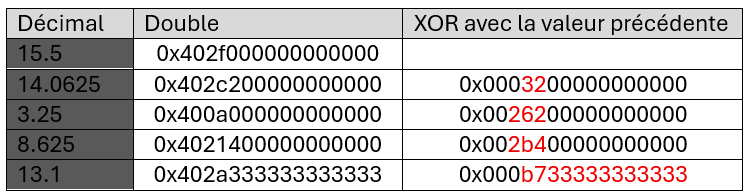
La première valeur est encodée sans compression. Pour les valeurs suivantes, une opération XOR est réalisée entre la valeur courante et la valeur précédente. Par définition, les bits inchangés valent alors ‘0’, tandis que les bits modifiés valent ‘1’.
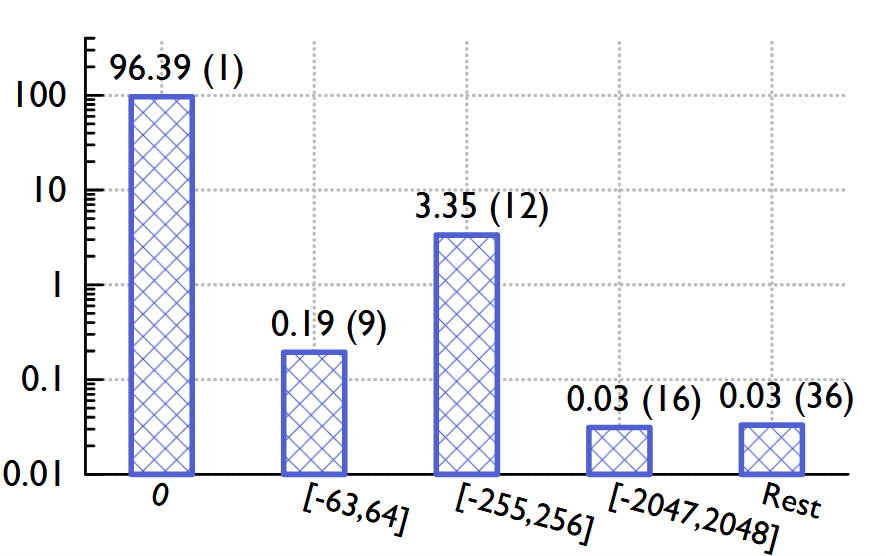
Si tous les bits sont à ‘0’ (autrement dit, si la valeur est identique à la précédente, ce qui est le cas pour 59% des valeurs étudiées par Facebook), un seul bit ‘0’ encode la valeur.
Dans le cas contraire, on enregistre un bit à ‘1’ et on détermine si les bits significatifs de la valeur courante sont dans la même plage que ceux des bits significatifs de la valeur précédente. Si c’est le cas, c’est-à-dire s’il y a au moins autant de bits inchangés au début et en fin de représentation (28% des valeurs), on enregistre un second bit à ‘0’ et on n’encode que la plage de bits significatifs. Sinon (13% des valeurs), le second bit est enregistré à ‘1’. On encode alors le nombre de zéros en tête de représentation sur 5 bits, le nombre de bits significatifs sur 6 bits, puis les bits représentatifs proprement dits.
Efficacité de l’encodage
Comme indiqué ci-dessus, dans un contexte de métrologie IT, la fréquence des dates associées aux valeurs dans une série chronologique est typiquement constante, ou presque. Les irrégularités liées aux variations temporelles des systèmes informatiques sont gommées par l’émetteur de la mesure, qui rapporte généralement la date planifiée de la mesure, plutôt que celle effective. En conséquence, les dates d’une série chronologique sont extrêmement prévisibles, si bien qu’on peut souvent encoder une date particulière par un seul bit ‘0’.
En ce qui concerne les valeurs mesurées, l’efficacité de l’encodage est plus sensible au contexte de mise en œuvre. Le principal paramètre de tuning est la longueur de la série chronologiques: plus celle-ci est grande, plus l’algorithme d’encodage est à même d’amortir les coûts d’encodage.
Sur l’infrastructure de Facebook, un découpage des séries chronologiques en tronçons de 2 heures permet un encodage sur 1,37 octet par point de mesure, contre 16 lorsque les séries chronologiques sont encodées naïvement. Cela correspond à une division du volume de stockage par 12, environ.
Adoption de l’algorithme Gorilla
Suite au succès de sa mise en œuvre par Facebook, l’algorithme d’encodage de Gorilla a été repris, étendu et adapté dans divers contextes. Je l’ai personnellement implémenté afin de stocker efficacement des données issues de capteurs industriels, avec un taux de compression similaire à celui observé par Facebook.
Son caractère générique en fait un bon candidat pour une implémentation dans une bibliothèque logicielle. Citons notamment une implémentation en Python qui supporte plusieurs types de valeurs.
Les bases de données Prometheus et VictoriaMetrics, spécialisées dans les séries chronologiques, supportent nativement cet encodage. Elles annoncent des gains en termes de stockage de la donnée parfois très impressionnants, mais à prendre avec des pincettes: des situations extrêmes, avec des données particulièrement stables, pouvant mener à des résultats favorables mais peu représentatifs de vos propres conditions d’utilisation.

Pingback: Gorilla: efficient encoding of time series – Myrmidons