Introduction
Une grande variété de systèmes informatiques actuels, du composant embarqué au serveur dans un data center, en passant par le smartphone et l’ordinateur portable, sont conçus pour l’exécution parallèle de tâches concurrentes: plusieurs programmes s’exécutent simultanément, sur une architecture à plusieurs processeurs. Les programmes eux-mêmes organisent leurs exécutions en processus, threads, et autres abstractions, ce qui permet une division fine en tâches pouvant s’exécuter de manière concurrente. À l’autre extrémité du spectre, une application peut être distribuées sur plusieurs machines, ce qui permet un parallélisation du travail sur une quantité arbitraire de ressources.
Cette parallélisation et cette concurrence permettent aux applications d’une part d’utiliser plus intensément les ressources disponibles (par exemple en réalisant des calculs sans attendre qu’une tâche indépendante ait fini d’utiliser une imprimante), et d’autre part d’utiliser davantage de ressources, et donc d’augmenter la capacité de traitement des logiciels.
Des problèmes …
On pourrait croire qu’avec les architectures modernes, les problèmes de l’époque héroïque, où les programmes se disputaient l’accès à des ressources aussi rares que chères, sont résolus. Au contraire, par certains aspects, ils ont même tendance à s’amplifier.
Certaines ressources informatiques restent rares, voire uniques. La plupart des ordinateurs n’ont qu’une carte réseau ou qu’une antenne WiFi, que les programmes doivent bien se partager. Plusieurs ordinateurs de bureau se partagent une imprimante. Un smartphone exécute des dizaines ou des centaines de processus simultanément, alors qu’il ne dispose, tout au plus, que de quelques processeurs.
Même lorsqu’un programme a la main sur une ressource, il ne peut en faire l’usage qu’il veut. Un logiciel de traitement de texte ne peut imprimer plusieurs pages simultanément. Si deux threads modifient simultanément une donnée, le résultat est incertain et la donnée peut même se retrouver dans un état incohérent.
… Et une solution
Pendant quelques décennies, la réponse à ces problématiques a consisté en des variantes autour de l’idée que l’accès à une ressource « restreinte » devait être protégé par un mécanisme de verrouillage. Quelque chose (typiquement, le système d’exploitation) garantit que seule l’entité possédant un passe-droit peut accéder à la ressource associée, et ce passe-droit n’est, à tout moment, donné qu’à un nombre restreint d’entités.
Cette approche a cependant des défauts qui la mettent à mal. Principalement, elle induit une baisse des performances. Plus une ressource est sollicitée, plus le système consacre de temps à gérer les mécanismes de verrouillage. Ceux-ci consomment eux-mêmes des ressources, forcément limitées, si bien qu’un compromis doit être réalisé entre la finesse du verrouillage (et donc le parallélisme permis) et le coût lié à sa gestion.
Une alternative: le modèle d’acteur
Le modèle d’acteur, popularisé par le langage de programmation Erlang, ne considère que l’acteur comme entité pour la programmation concurrente. Les acteurs communiquent par l’envoi et la réception de messages. Chaque acteur dispose d’une « boîte aux lettres » dans laquelle on peut déposer un message. L’acteur réceptionne et traite ses messages l’un après l’autre et peut y réagir en émettant un nouveau message, en créant un nouvel acteur, ou en effectuant un traitement local. Tout comme pour le courrier postal, l’émission et le traitement des messages sont asynchrones, ce qui facilite grandement la parallélisation de l’application.
Chaque acteur possède un état interne qu’il garde secret: il n’est possible ni de le consulter, ni de le modifier autrement que par l’échange de messages.
On programme les acteurs de sorte qu’ils organisent le travail à réaliser. On peut les comparer aux robots d’une chaîne de montage: chacun est spécialisé dans une tâche, sait quoi faire d’un élément reçu et sait à qui le transmettre une fois son travail terminé.
Ce modèle fait disparaître le besoin de gestion de verrous. Si une ressource est unique (une imprimante, par exemple), il est possible d’en donner la gestion à un acteur qui en protège l’accès en considérant l’état de la ressource comme faisant partie de son propre état. Pour imprimer un document, un autre acteur peut soumettre un message à l’acteur en charge de l’imprimante, et ce message sera traité lorsque l’état de la ressource le permettra.
L’état interne des acteurs n’étant pas directement accessible, on bénéficie des avantages de l’immuabilité procurée par la programmation fonctionnelle. Plusieurs threads, processus, ou mêmes ordinateurs, peuvent travailler sur les mêmes données, puisqu’elles ne peuvent être (directement) altérées. Le risque de race condition disparaît. Le mécanisme de gestion des acteurs peut planifier efficacement leur exécution, y compris à grande échelle, car il n’est pas nécessaire d’assurer la synchronisation de leurs états respectifs. Une parallélisation automatique très poussée est dès lors possible.
Ce modèle offre une grande modularité: chaque acteur peut être testé indépendamment, puis être intégré au sein d’un écosystème d’acteurs en fonction des besoins de l’application. On retrouve ici les avantages (et certains inconvénients) des micro-services, mais dans un système intra-applicatif.
Par nature, il se prête très bien à la programmation réactive, qui consiste essentiellement à réagir de manière asynchrone à l’occurrence de certains événements. Il est mis en œuvre avec succès dans les environnements hautement concurrents, notamment par Ericsson pour la gestion de nœuds de communication.
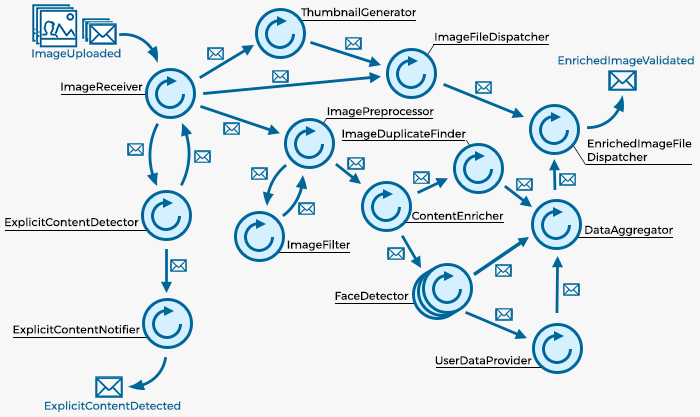
Pekko et Pekko Stream
Apache Pekko est un fork de Akka, un framework en Scala et Java basé sur le modèle d’acteur. Le fork est dû à des questions de licence, mais d’un point de vue technique, les deux outils sont pratiquement identiques.
Pekko propose une implémentation du modèle d’acteur en permettant l’échange de messages fortement typés sur un ensemble d’acteurs organisés de manière hiérarchique. Il gère l’exécution asynchrone et concurrente des acteurs, tout en permettant leur distribution aussi bien au sein d’une application qu’entre plusieurs machines connectées en réseau. Un serveur doté de 16 Go de RAM peut aisément supporter plusieurs millions d’acteurs Pekko.
Alors que le modèle d’acteur est extrêmement flexible (tous les acteurs peuvent, en principe, communiquer avec tous les autres), il est, en pratique, souvent mis en œuvre pour concevoir des graphes de traitement plus structurés. On souhaite en effet généralement organiser les flux de communication entre acteurs sous la forme de graphes. Pekko propose Pekko Stream, un mécanisme basé sur le modèle d’acteurs, pour faciliter cette organisation.
Avec Pekko Stream, le développeur manipule trois types de composants primitifs:
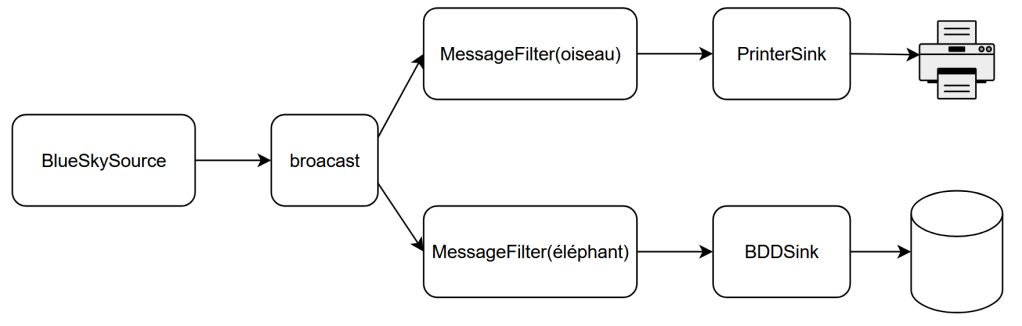
- Les sources, qui sont des composants ne consommant rien et produisant un flux d’éléments. On pourrait imaginer un BlueSkySource, qui produit un flux de messages BlueSky au fur et à mesure que ceux-ci sont publiés par la plate-forme.
- Les sinks, qui sont des composants consommant un flux d’éléments et ne produisant rien. On peut imaginer un DatabaseSink qui consomme un flux de messages BlueSky et les stocke dans une base de données, ou un PrintSink qui consomme le même flux de messages et les imprime.
- Les flows, qui sont des composants qui consomment un flux d’éléments et produisent un autre flux d’éléments. On pourrait imaginer un flow BirdFilter, qui consomme un flux de messages BlueSky et produit un flux ne contenant que les messages consommés relatifs aux oiseaux.
Pekko Stream propose tout un ensemble d’autres outils gravitant autour de ces trois composants de base. Il est possible de définir des composants consommant et produisant un nombre arbitraire de flux. Un composant standard duplique un flux donné en entrée sur plusieurs sorties. Un autre accumule temporairement les messages qu’il consomme pour en produire une synthèse à intervalle régulier. Pekko Stream est donc une solution technologique appropriée pour l’implémentation quasiment littérale des patrons d’intégration d’entreprise.
Lorsqu’il met en œuvre Pekko Stream, le développeur décrit ou sélectionne les composants qu’il souhaite exploiter. Il décrit ensuite la manière dont il souhaite les assembler. Il s’agit là d’une description, et non d’une implémentation: le résultat est semblable au plan d’un architecte, qu’un mécanisme se charge de convertir en éléments concrets au sein du système informatique. Ce découplage entre conception et implémentation permet une flexibilité et une adaptabilité dans l’exploitation des graphes Pekko ainsi conçus. Le mécanisme se charge notamment de décider la manière dont les composants du graphe doivent être traduits en acteurs Pekko.
Pekko offre de plus quelques propriétés qui me semblent particulièrement intéressantes.
Composabilité et réutilisabilité
Une fois conçu, un composant peut être manipulé en ne se basant que sur son interface, c’est-à-dire les flux qu’il consomme et ceux qu’il produit. Celle-ci étant explicite, il est très simple de reprendre le plan d’un composant pour adapter ses entrées et sorties à de nouveaux composants. Si un plan est paramétrisé, il peut être décliné en de nouveaux composants pour répondre à différents besoins.
Par exemple, notre flow ne retenant que certains posts de BlueSky peut avoir pour paramètre le mot servant de critère de filtrage. Vous pouvez alors créer une instance du flow pour ne retenir que les messages parlant d’oiseaux, ou bien ceux parlant d’éléphants. Et pourquoi pas les deux en même temps: les messages relatifs aux oiseaux étant destinés à être imprimés, tandis que ceux relatifs aux éléphants seraient stockés dans une base de données.
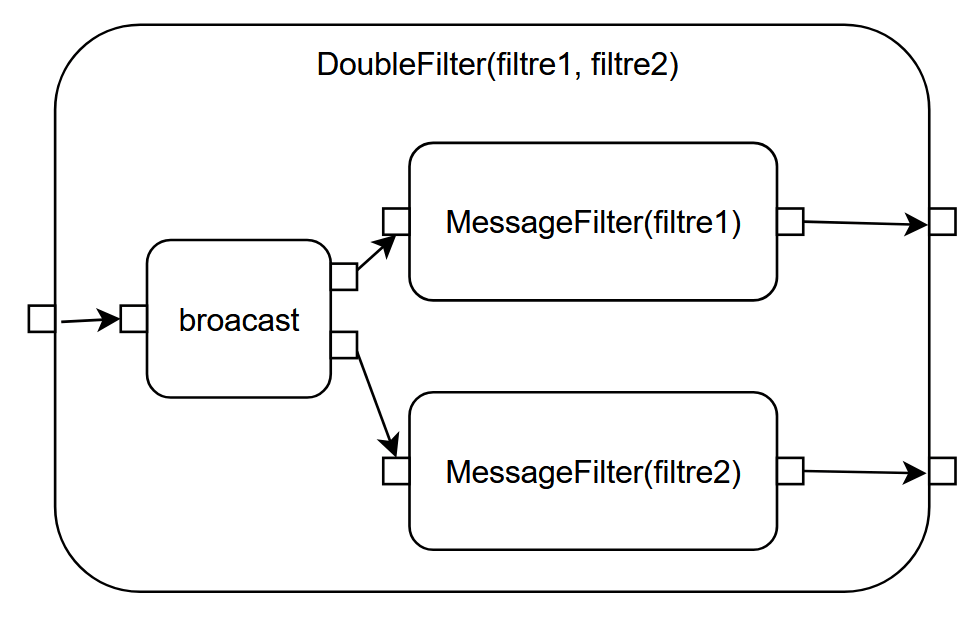
La composabilité vient du fait qu’il est possible d’emboîter les composants les uns dans les autres et des chaîner les uns après les autres. Des composants élémentaires peuvent être combinés en des graphes partiels, c’est-à-dire que certaines des entrées ou sorties des composants ne sont connectées à rien. On crée alors un composant de plus haut niveau qui encapsule les composants élémentaires en connectant ses propres entrées et sorties à celles laissées vacantes dans les composants élémentaires. Par exemple, si on se rend compte que la division du flux de messages BlueSky en deux flux filtrés est une pratique récurrente, il peut être intéressant de créer un composant DoubleFilter. On réduit ainsi les assemblages à réaliser.
DoubleFilter étant lui-même un composant, il peut être utilisé et réutilisé à volonté, sans plus avoir à se soucier des détails de son fonctionnement interne.
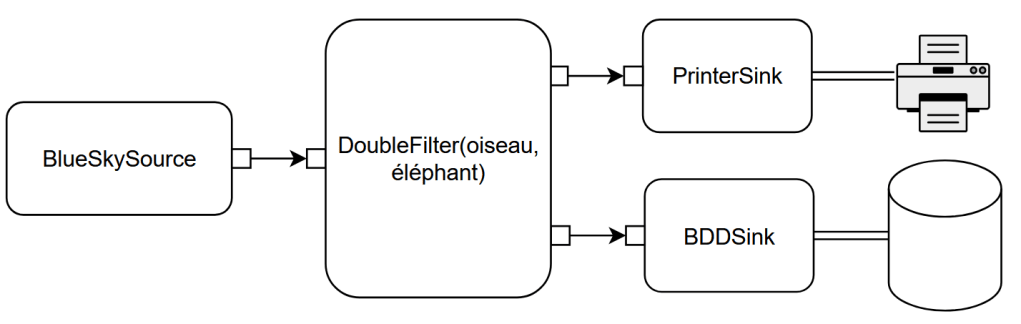
Cet extrême niveau de composabilité et de réutilisabilité permet de concevoir des composants, y compris très complexes, et de les « poser sur l’étagère » pour qu’ils soient repris par d’autres pour créer de nouveaux agencements et de nouveaux composants encore plus complexes. C’est par exemple ce qui est fait au sein même du projet Pekko avec Pekko HTTP, une bibliothèque proposant un client et un serveur HTTP qui reposent sur Pekko Stream.
Un DSL un peu particulier
Ces schémas sont bien beaux, mais il est aisé de cacher un programme abominable derrière de petites boîtes connectées par de petites flèches.
Prenons l’exemple d’un graphe non trivial.

Concrètement, en Java, les composants sont créés comme autant d’objets, et les relations entre composants sont exprimés par des appels de méthodes sur les objets qui les représentent. Tout ce qu’il y a de plus classique, mais le code ainsi produit est assez moche.
final Graph<FlowShape<Integer, Integer>, NotUsed> partial =
GraphDSL.create(
builder -> {
final UniformFanOutShape<Integer, Integer> B = builder.add(Broadcast.create(2));
final UniformFanInShape<Integer, Integer> C = builder.add(Merge.create(2));
final UniformFanOutShape<Integer, Integer> E = builder.add(Balance.create(2));
final UniformFanInShape<Integer, Integer> F = builder.add(Merge.create(2));
builder.from(F.out()).toInlet(C.in(0));
builder.from(B).viaFanIn(C).toFanIn(F);
builder
.from(B)
.via(builder.add(Flow.of(Integer.class).map(i -> i + 1)))
.viaFanOut(E)
.toFanIn(F);
return new FlowShape<Integer, Integer>(B.in(), E.out(1));
});
Il est possible d’utiliser un SDK très similaire en Scala, mais, pour ce langage, on préfère le plus souvent utiliser un DSL interne. Concrètement, il s’agit de pur code Scala (il est entièrement supporté par un IDE supportant Scala, notamment), mais il utilise la flexibilité du langage pour offrir une représentation plus visuelle des composants.
import GraphDSL.Implicits._
val partial = GraphDSL.create() { implicit builder =>
val B = builder.add(Broadcast[Int](2))
val C = builder.add(Merge[Int](2))
val E = builder.add(Balance[Int](2))
val F = builder.add(Merge[Int](2))
C <~ F
B ~> C ~> F
B ~> Flow[Int].map(_ + 1) ~> E ~> F
FlowShape(B.in, E.out(1))
}
Les lignes 3 à 6 décrivent chacun des composants qui seront impliqués dans le graphe. La ligne 11 indique que le graphe est un Flow, dont l’entrée correspond à l’entrée de B, et la sortie correspond à la sortie numéro 1 de E.
Les lignes 8 à 10 sont, selon moi, les plus intéressantes. Ces flèches ondulées sont en réalité des méthodes qui définissent les relations entre les composants. Par exemple, la ligne 8 indique que la sortie de F doit être connectée à la première entrée de C. La ligne suivante indique que la sortie de B doit être connectée à la seconde entrée de C, et que la sortie de C doit être connectée à la première entrée de F.
Que vous utilisiez le SDK « classique » ou la forme plus visuelle du DSL, la description des composants reste entièrement programmatique. Il est donc tout à fait possible de les définir dynamiquement, par exemple en ne plaçant un composant que sous certaines conditions. En pratique, cependant, les composants sont définis de manière statique dans la plupart des cas.
Un riche catalogue de composants
Un autre avantage majeur de Pekko est la mise à disposition des développeurs de tout un catalogue de connecteurs. Outre la connexion à des bases de données (relationnelles, Cassandra, ElasticSearch, …) et à des flux de données (Kafka, MQTT, AWS SQS, …), il donne accès à des solutions de stockage et des formats de fichiers tels que FTP, AWS S3, Parquet, etc.
La concurrence du projet Loom
On pourrait, en 2025, douter de l’intérêt du modèle d’acteur. Les langages de programmation et les bibliothèques logicielles plus classiques proposent régulièrement des avancées dans le domaine de la performance et du parallélisme. Par exemple, le projet Loom revoit la manière dont la JVM gère ce parallélisme. Un point clef du projet consiste à remplacer les threads directement traduits en threads du système d’exploitation sous-jacent par des threads virtuels, beaucoup plus légers. La JVM se chargeant de coordonner leur exécution sur un nombre maîtrisé de threads système. Plutôt que de chercher à réutiliser un nombre restreint de threads au sein d’un pool, le développeur peut alors créer un très grand nombre de threads virtuels, un pour chaque tâche à réaliser, ce qui est plus simple.
Le modèle d’acteur n’a cependant pas dit son dernier mot. Avant tout gain (potentiel) de performance, il propose une approche différente du découpage du travail en tâches, et leur planification dans un système distribué. Le remplacement des données partagées par l’échange de messages est un changement de paradigme qui conserve ses propres avantages. En particulier, le modèle d’acteur permet une exécution sur plusieurs systèmes de manière transparente pour le développeur.
Les threads virtuels ne suppriment pas le besoin de gérer le verrouillage des ressources partagées ainsi que la synchronisation entre threads. L’apparition de dead locks reste possible, et doit donc toujours être gérée.
Lorsque la synchronisation est importante, elle induit toujours une baisse des performances, les threads consacrant un temps non négligeables à s’arranger entre eux plutôt qu’à travailler.
Les bibliothèques construites sur base du modèle d’acteur, telle que Pekko Stream, proposent des solutions innovantes pour représenter la gestion de flux complexes de données. Elles profitent de la grande autonomie des acteurs ainsi que de leur capacité à se combiner pour permettre la conception de briques logicielles extrêmement composables et réutilisables.
Pekko Stream offre également un mécanisme de back pressure. La capacité de la boîte au lettre d’un composant est limitée à 5 ou 10 messages. Si la consommation des messages est plus lente que leur production, plutôt que d’accumuler les messages en attente dans la boîte au lettre, Pekko Stream informe les producteurs du problème et les obligent à ralentir la production. Les producteurs peuvent à leur tour ne plus pouvoir suivre la cadence des messages qu’ils reçoivent, et l’ordre de ralentissement se répercute progressivement afin d’éviter la congestion du graphe de traitement. Il est fréquent que les sources d’un graphe soient basées sur une file de messages (par exemple, Apache Kafka) qui agit comme tampon de grande capacité.
Malgré les avantages propres au modèle d’acteur, son intégration avec le projet Loom reste très prometteur. Par exemple, chaque acteur pourrait disposer de son propre thread virtuel, ce qui le rendrait plus efficace. La gestion des threads reviendrait à la JVM, plutôt qu’à une bibliothèque tierce, ce qui permettrait de tirer profit des avancées réalisées au cœur de la machine.
Conclusion
En tant que développeurs, nous sommes amenés à trouver de nouvelles solutions aux problèmes soulevés par la distribution et la parallélisation de nos composants logiciels.
Des projets à large spectre, comme le projet Loom, sont une partie de la réponse. Mais, comme nous l’avons vu, il reste des questions fondamentales qui deviennent critiques pour nos systèmes massivement parallèles et distribués. Le modèle d’acteur offre un changement de paradigme qui apporte une manière éprouvée de répondre à ces questions.
Des implémentations modernes de ce modèle permettent la conception de composants de traitement de flux de données fortement réutilisables, ce qui constitue actuellement un objectif stratégique pour de nombreuses entreprises.
Plutôt que de les concurrencer, ces implémentations vont bénéficier des avancées offertes par des projets comme Loom. En offrant des bases plus saines et plus adaptées aux besoins modernes au cœur même de la JVM, ceux-ci démultiplieront les avantages du modèle d’acteur.
